上篇文章写了复合信度的计算,今天给大家写一写聚合效度的R语言计算方法。欢迎交流。
聚合效度简介
聚合效度( )是指运用不同测量方法测定同一特征时测量结果的相似程度,即不同测量方式应在相同特征的测定中聚合在一起。它又叫做收敛效度,是指测量相同潜在特质(构念)的测验指标会落在同一共同因素上。
聚合效度的最常见的一个表示指标就是平均变异抽取量〈 , AVE〉在模型中引入解释变量,我们再来看看AVE的计算公式:
大家应该会发现AVE的公式跟组合信度CR的公式长得非常接近,没错在模型中引入解释变量,它们的差别只是在CR是先将因素负荷量加总之后才求平方,但AVE是将因素负荷量求平方之后才加总。
根据公式我们就可以知道AVE的意义非常:每一个题目(观察变量)的变异数被标准化为1,从而「δ + λ 2=1」,因此公式的分子代表的是「潜在变量可解释观察变量的解释力总和」,而分母表示「观察变量的总变异数」,另外还有一个比较好玩的是:事实上,分母就只是「观察变项的数目」,因此AVE的公式就只是把因素负荷量平方的加总再除以题目数量而已,因此AVE也是指「SMC或R 2的平均值」。
R语言计算实操
这部分,不玩虚的,还是手把手教学:
而且前面的大部分内容和上一篇文章相似:R数据分析:如何计算问卷的组合信度,实例操练
导入数据,这个数据也是上篇写探索性因子分析时用的数据:R数据分析:探索性因子分析
data<-read.csv(file.choose(),header=TRUE)输入以上代码选择数据文件EFA.csv(请私信获取),就导入完成。
上篇文章探索性因子分析做出来不是4个因子嘛,我们取其中一个因子给大家写如何做这个因子的聚合效度,我们需要用到这个包:
然后构建模型,拟合模型一气呵成:
library(lavaan)model<-'value=~Price +Resale_Value +Maintenance +Fuel_Efficiency'fit <- cfa(model, data = data)然后,我们需要有标准化的因子载荷,此时就需要函数:
s1<-standardizedSolution(fit)s1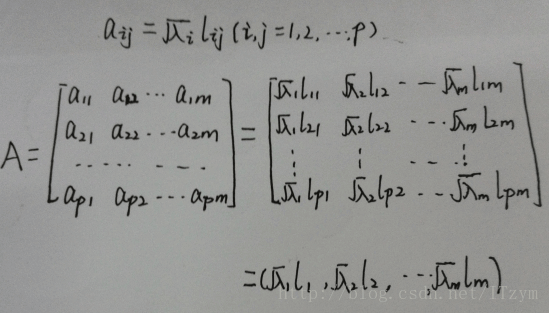

输出如下:
我们需要的其实就是est.std(est.std就是标准化的估计值)这一列的载荷部分,所以得进行选取:
s1 <- s1$est.std[s1$op == "=~"]#选出了测量部分的标准化载荷然后我们就可以套公式啦,首先计算残差方差,然后聚合效度就出来啦:
re <- 1 - s1^2sum(s1^2) / (sum(s1^2) + sum(re))还有因为我们是用4个指标做了一个验证性因子分析,上面的计算公式中的分母部分sum(s1^2) + sum(re)的结果其实就是4。这个也是说其实聚合效度就是因子标准化载荷平方和的均值。
大家可以看到,实际上所有的操作和组合信度不同的就是在最后一步改变了计算公式,其实在实际的数据分析中,我们可以很方便的同时计算出问卷的组合信度和聚合效度。
小结
今天给大家写了问卷聚合效度的R语言计算方法,感谢大家耐心看完。发表这些东西的主要目的就是督促自己,希望大家评论指出不足,一起进步。内容我都会写的很细,用到的数据集也会在原文中给出链接,你只要按照文章中的代码自己也可以做出一样的结果,一个目的就是零基础也能懂,因为自己就是什么基础没有从零学和R的,加油。
(站外链接发不了,请后私信回复“数据链接”获取本头条号所有使用数据)
往期内容:
R数据分析:探索性因子分析
R语言作图:如何在数据可视化过程中调整因子顺序
R数据分析:如何用R做验证性因子分析及画图,实例操练
文献解析:结构方程模型的基础知识
R数据分析:结构方程模型画图以及模型比较,实例操练
R可视化:的常用操作总结
本文到此结束,希望对大家有所帮助。
本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至81118366@qq.com举报,一经查实,本站将立刻删除。发布者:简知小编,转载请注明出处:https://www.jianzixun.com/80098.html
 微信扫一扫
微信扫一扫  支付宝扫一扫
支付宝扫一扫